UDS DoIP Large File Transfer
This example demonstrates how to transfer large binary files to an ECU using UDS (Unified Diagnostic Services) over DoIP with streaming file reading. This approach is optimized for handling very large files without loading the entire file into memory at once.
Overview
The example implements a large file transfer sequence using the following UDS services:
- RequestDownload (0x34) - Initiates the download process
- TransferData (0x36) - Transfers data chunks in sequence
- RequestTransferExit (0x37) - Completes the transfer process
Key Innovation: Streaming vs Traditional Approach
Traditional Approach (Previous Examples
typescript
// OLD: Loads entire file into memory at once
const hexStr = await fsP.readFile(hexFile, 'utf8')
const map = HexMemoryMap.fromHex(hexStr)
for (const [addr, data] of map) {
pendingBlocks.push({ addr, data }) // All data loaded into memory
}Limitations:
- ❌ High memory consumption for large files
- ❌ Risk of out-of-memory errors with multi-GB files
- ❌ Slower startup time for large files
- ❌ Cannot handle files larger than available RAM
Streaming Approach (This Example)
typescript
// NEW: Opens file handle for streaming reads
fHandle = await fsP.open(hexFile, 'r')
// Read only what's needed for current transfer
const data = Buffer.alloc(maxChunkSize)
const { bytesRead } = await fHandle.read(data)Advantages:
- ✅ Memory Efficient: Only loads small chunks at a time
- ✅ Scalable: Can handle files of any size (GB+)
- ✅ Fast Startup: Begins transfer immediately
- ✅ Real-time Processing: Reads data as it's needed
- ✅ Lower Resource Usage: Minimal memory footprint
Architecture & Flow
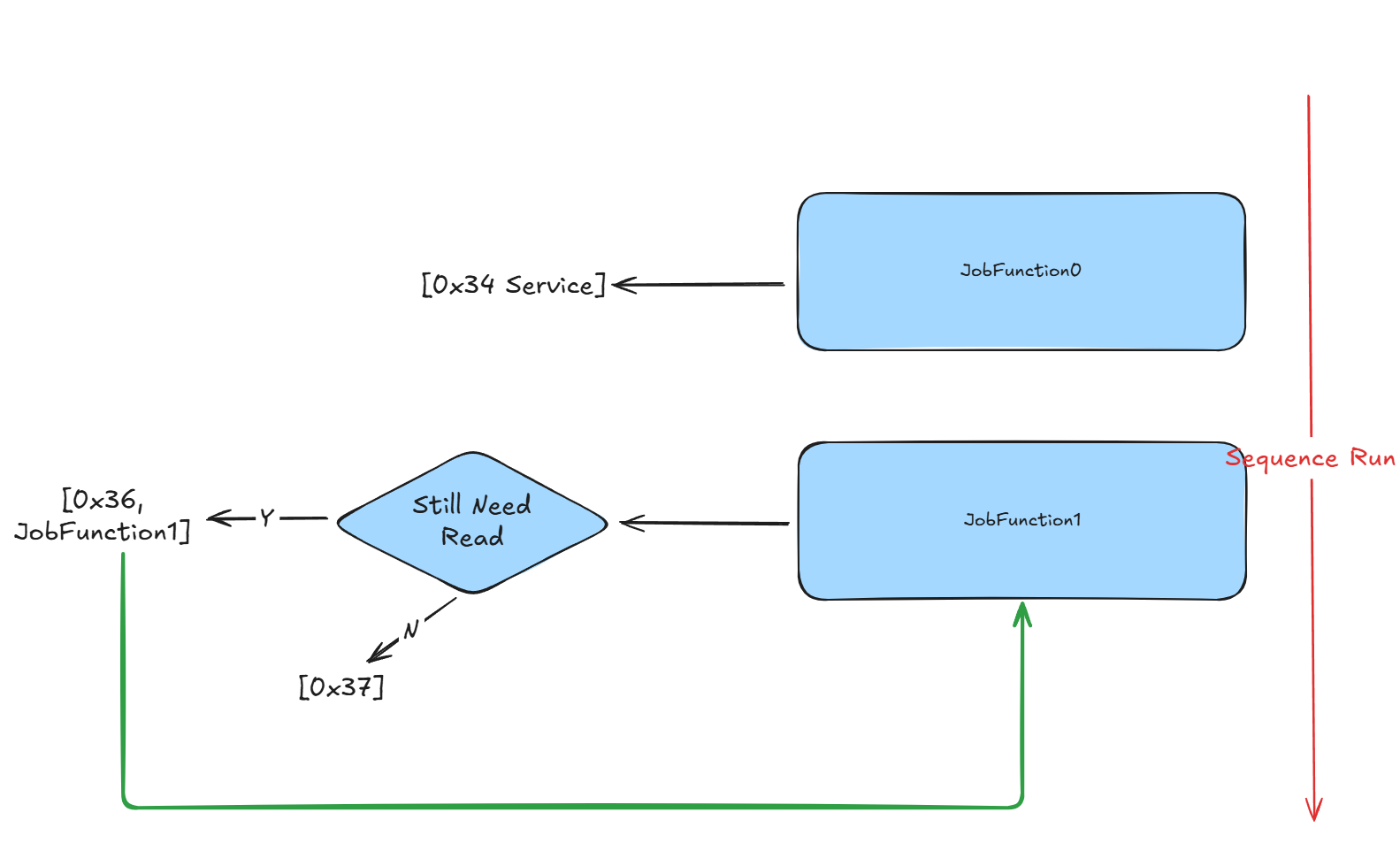
The transfer process follows this sequence:
- JobFunction0: Initiates download request and receives ECU capabilities
- "Still Need Read" Decision: Determines if more data needs to be transferred
- JobFunction1: Performs chunked data transfer with streaming reads
- Sequential Processing: Continues until entire file is transferred
Implementation Details
File Streaming Setup
typescript
let fHandle: fsP.FileHandle | undefined
Util.Init(async () => {
const hexFile = path.join(process.env.PROJECT_ROOT, 'large.bin')
fHandle = await fsP.open(hexFile, 'r') // Open for streaming
})
Util.End(async () => {
if (fHandle) {
await fHandle.close() // Proper cleanup
}
})JobFunction0 - Download Initiation
Prepares the ECU for receiving data and negotiates transfer parameters:
typescript
Util.Register('Tester.JobFunction0', async () => {
if (fHandle) {
const fileState = await fHandle.stat()
console.log('File size:', fileState.size)
const r34 = DiagRequest.from('Tester.RequestDownload520')
const memoryAddress = Buffer.alloc(4)
memoryAddress.writeUInt32BE(0)
r34.diagSetParameterRaw('memoryAddress', memoryAddress)
r34.diagSetParameter('memorySize', fileState.size)
r34.On('recv', (resp) => {
// Get max chunk size from ECU response
maxChunkSize = resp.diagGetParameterRaw('maxNumberOfBlockLength').readUint32BE(0)
maxChunkSize -= 2 // Account for sequence counter
// Align to 8-byte boundary for optimal transfer
if (maxChunkSize & 0x07) {
maxChunkSize -= maxChunkSize & 0x07
}
})
return [r34]
}
return []
})JobFunction1 - Streaming Data Transfer
Performs the actual file transfer using streaming reads:
typescript
Util.Register('Tester.JobFunction1', async () => {
if (fHandle) {
const list = []
const data = Buffer.alloc(maxChunkSize) // Reusable buffer
// Transfer multiple chunks per batch (combine36 = 6)
for (let i = 0; i < combine36; i++) {
const { bytesRead } = await fHandle.read(data) // Stream read
const transferRequest = DiagRequest.from('Tester.TransferData540')
transferRequest.diagSetParameterSize('transferRequestParameterRecord', bytesRead * 8)
transferRequest.diagSetParameterRaw(
'transferRequestParameterRecord',
data.subarray(0, bytesRead) // Only send actual data
)
// Block sequence counter (1-255 rolling)
const blockSequenceCounter = Buffer.alloc(1)
blockSequenceCounter.writeUInt8(cnt & 0xff)
transferRequest.diagSetParameterRaw('blockSequenceCounter', blockSequenceCounter)
cnt++
list.push(transferRequest)
// Check if more data available
if (bytesRead == maxChunkSize) {
if (i == combine36 - 1) {
// Continue with next batch
list.push(DiagRequest.from('Tester.JobFunction1'))
}
} else {
// End of file reached
console.log(`Read ${bytesRead} bytes, no more data to read.`)
// Send transfer exit request
const r37 = DiagRequest.from('Tester.RequestTransferExit550')
r37.diagSetParameterSize('transferRequestParameterRecord', 0)
list.push(r37)
// Cleanup
await fHandle.close()
fHandle = undefined
break
}
}
return list
}
return []
})Memory Usage Comparison
| Approach | 1GB File | 4GB File | 10GB File |
|---|---|---|---|
| Traditional | ~1GB RAM | ~4GB RAM | ~10GB RAM |
| Streaming | ~4KB RAM | ~4KB RAM | ~4KB RAM |
Use Cases
This streaming approach is ideal for:
- ECU firmware updates with large binary files
- Calibration data transfer for automotive applications
- Software deployment to embedded systems
- Data logging and diagnostic information transfer
- Any scenario requiring memory-efficient large file transfers
This implementation represents a significant improvement over traditional approaches, enabling reliable transfer of very large files in resource-constrained environments.